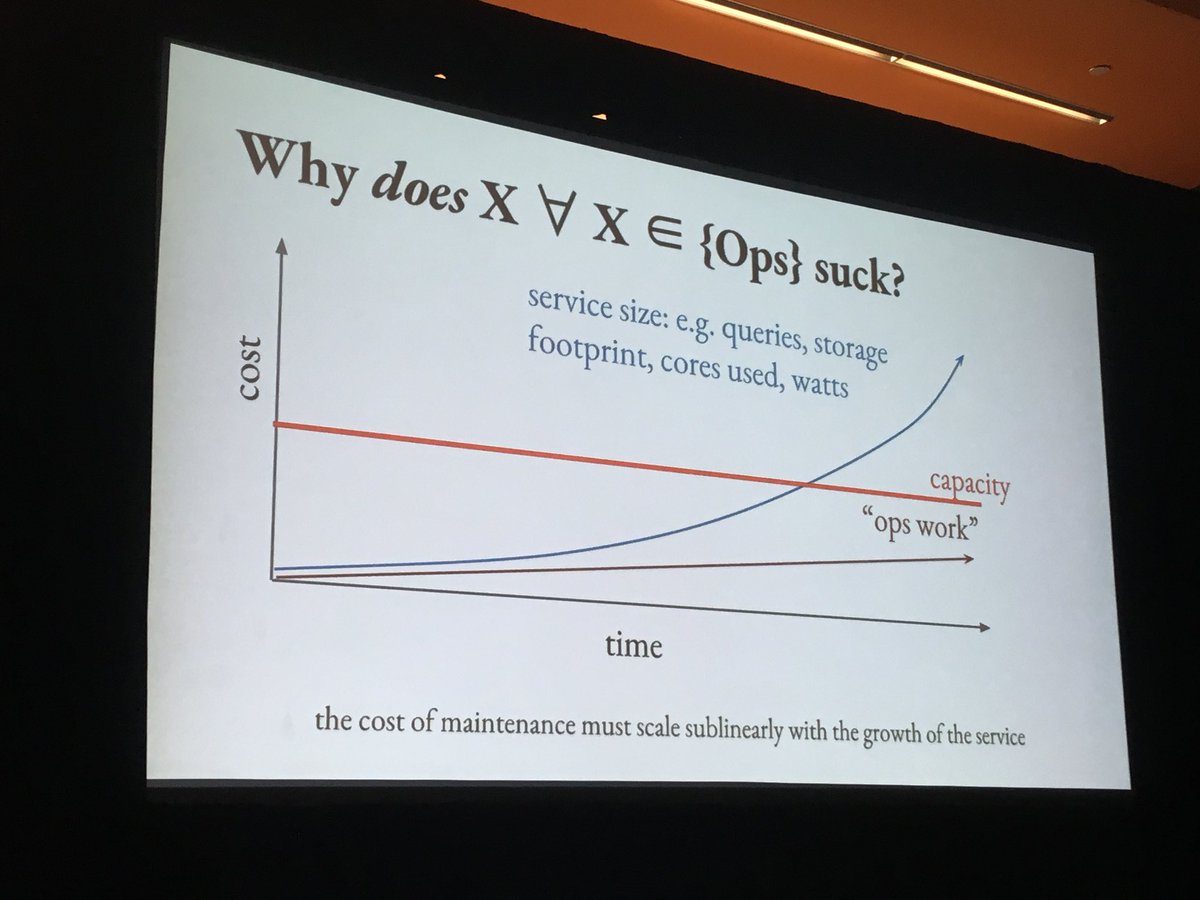
The distributed real time telemetry challenge at NS1
- 5-700K data points per sec
- avg of 200K data points per second (terabytes per day)
- why an OpenTSDB approach failed (DDOS attack mitigation required more granular telemetry and per packet inspection)
- why ELK made sense
- 5-700K data points per sec
- avg of 200K data points per second (terabytes per day)
- why an OpenTSDB approach failed (DDOS attack mitigation required more granular telemetry and per packet inspection)
- why ELK made sense




“Given all the problems we had, we decided that we needed to pick a tool that had a solid community behind it. We wanted to gain from a flourishing community and wanted to contribute back” - why ELk was chosen as a long term time series database at @NS1


openTSDB still wins hands down for analytics purposes but NS1 didn’t need that. OpenTSDB requires deep operational expertise to tune, scale and run which NS1 didn’t want to invest in.
The used the beats ecosystem (beats is the oss project from eBay, iirc)
The used the beats ecosystem (beats is the oss project from eBay, iirc)

high cardinality values like IP address (especially for a globally distributed authoritative DNS service like NS1), OpenTSDB can’t index and query for these values.
On where ELK shines over standard time series databases. #velocityconf
On where ELK shines over standard time series databases. #velocityconf


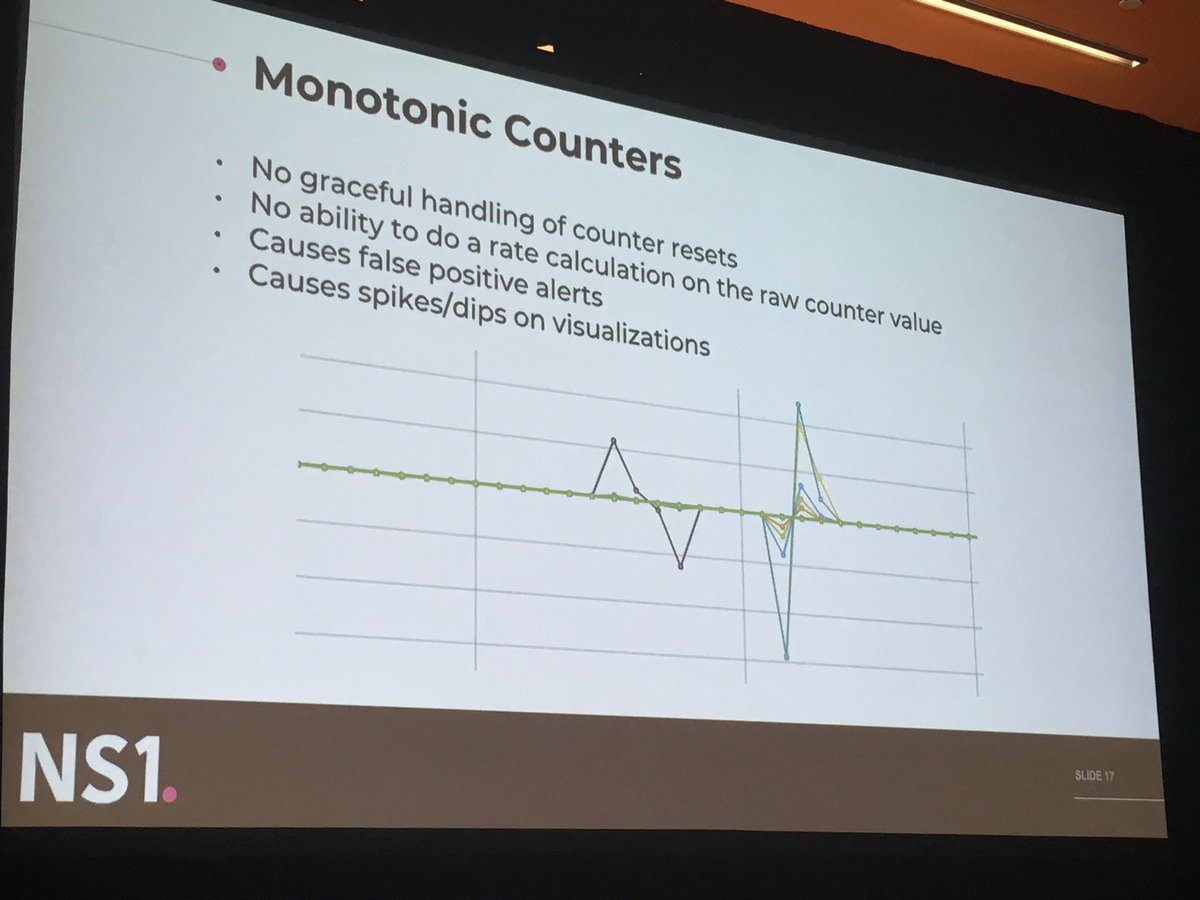
Where ELK actually falls short as a time series database:
- downsampling
- monotonous counters and operations related to counters
#velocityconf
- downsampling
- monotonous counters and operations related to counters
#velocityconf

TLDR of this talk -
- high cardinality is a requirement
- need a system that combines the best of metrics and logs
- operational simplicity and community
- ELK has a steep learning curve which discouraged NS1 at first, but community support helped overcome these barriers
- high cardinality is a requirement
- need a system that combines the best of metrics and logs
- operational simplicity and community
- ELK has a steep learning curve which discouraged NS1 at first, but community support helped overcome these barriers


The benefits of having a single system for telemetry and logs.
Also - kudos to the speaker for keeping the y’all buzzword free, and using terms like “Operations engineer” and “monitoring” 👏
Also - kudos to the speaker for keeping the y’all buzzword free, and using terms like “Operations engineer” and “monitoring” 👏


Q&A time at #velocityconf
Why did NS1 pick Kibana over grafana?
A: the devs (backend engineers) like grafana better and that’s what they use. The operations team require the ability to make certain Elasticsearch queries which grafana doesn’t support, so that team uses Kibana”
Why did NS1 pick Kibana over grafana?
A: the devs (backend engineers) like grafana better and that’s what they use. The operations team require the ability to make certain Elasticsearch queries which grafana doesn’t support, so that team uses Kibana”
Q: why ELK instead of @InfluxDB?
A: NS1 needed clustering support which isn’t available in the OSS InfluxDB.
A: NS1 needed clustering support which isn’t available in the OSS InfluxDB.
• • •
Missing some Tweet in this thread? You can try to
force a refresh