
Next up at #velocityconf its the one and only @jaqx0r - Google SRE extraordinaire on how best to monitor with SLO’s 

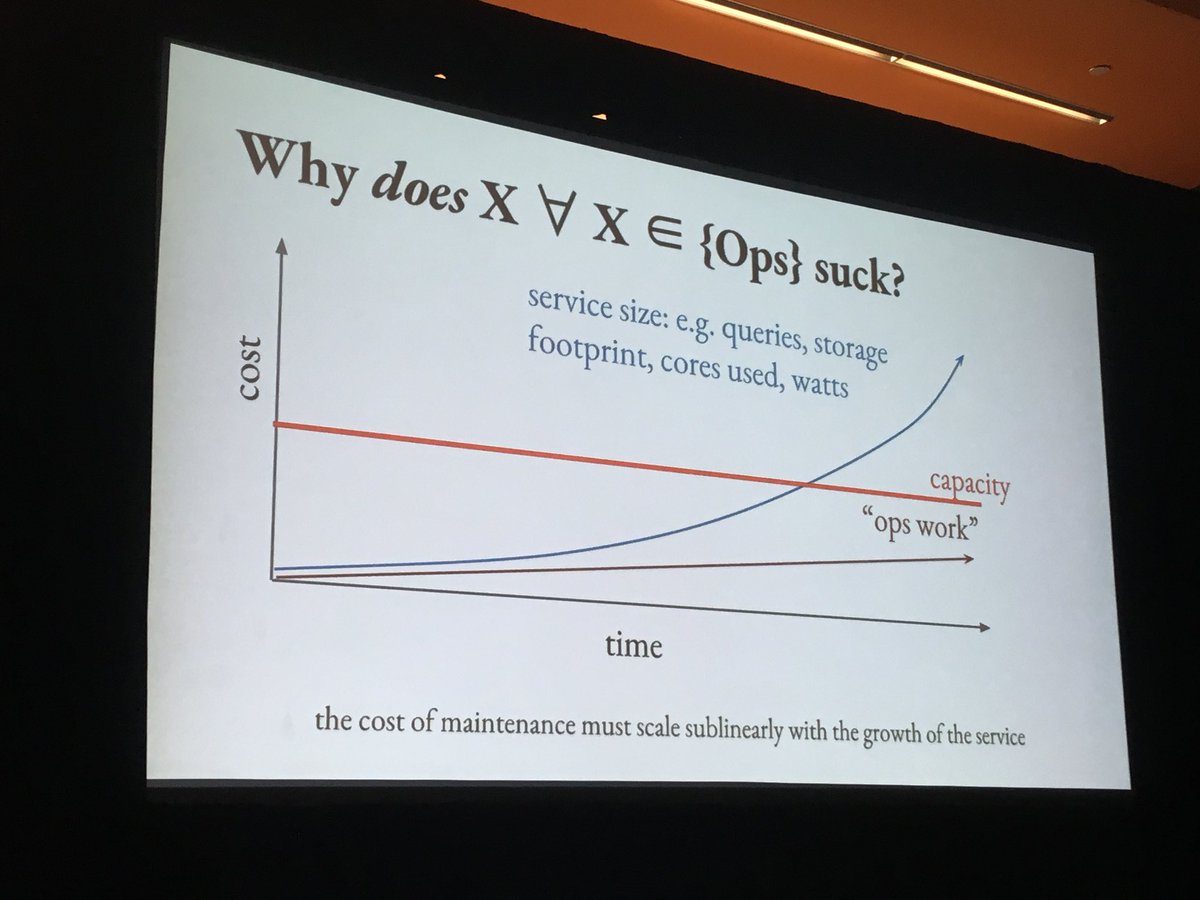
The cost of maintenance of a system must scale sublinearly with the growth of the service - #velocityconf
At Google, Ops work needs to be less than 50% of the total work done by SRE
At Google, Ops work needs to be less than 50% of the total work done by SRE
Once you have an SLO that’s really not an SLO since the users have come to expect better, then you’re unable to take any risks. Systems that are *too* reliable can become problematic too. #VelocityConf




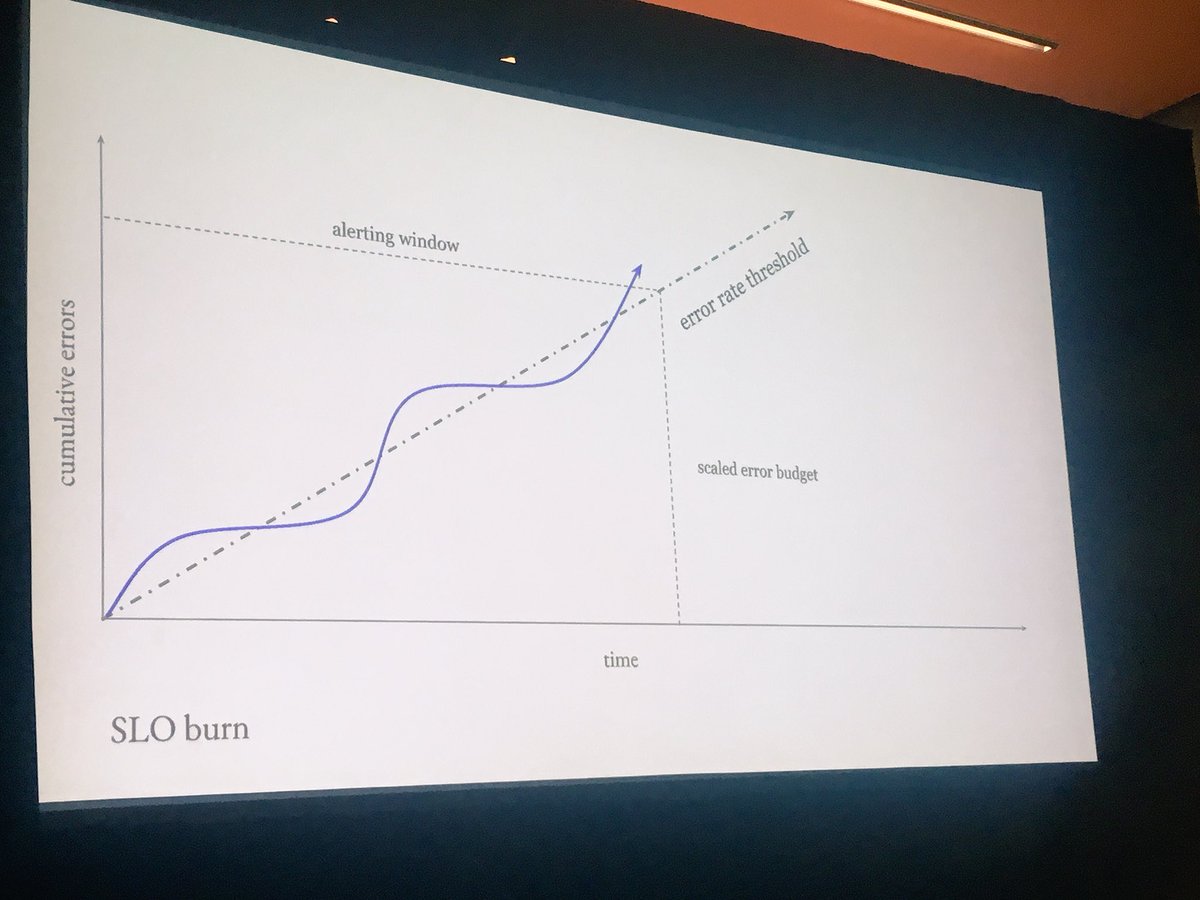
Alerts need to be informed by both the SLO and the error budget. # velocityconf
At Google, burning an error budget within 24 hours is worth an alert.
At Google, burning an error budget within 24 hours is worth an alert.


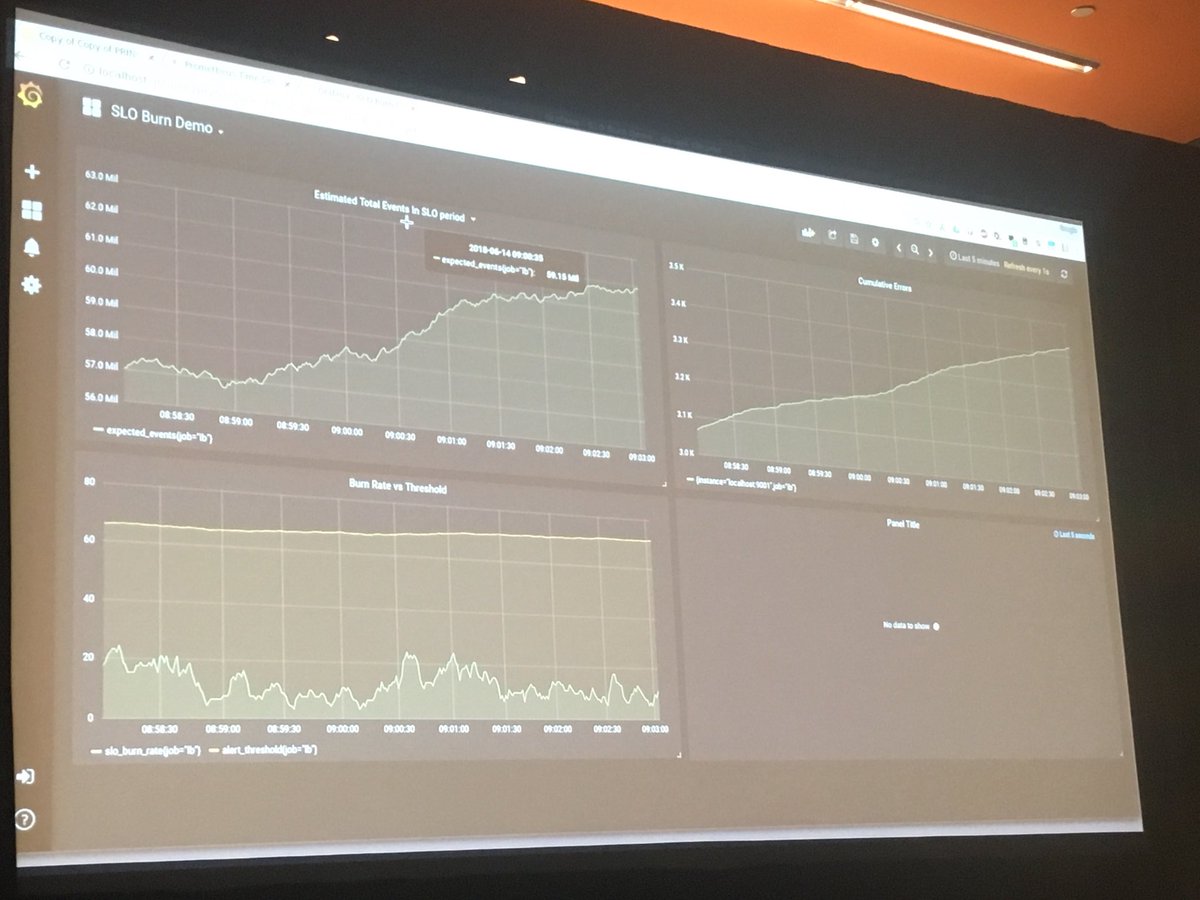
How to monitor SLO burn with @PrometheusIO #velocityconf
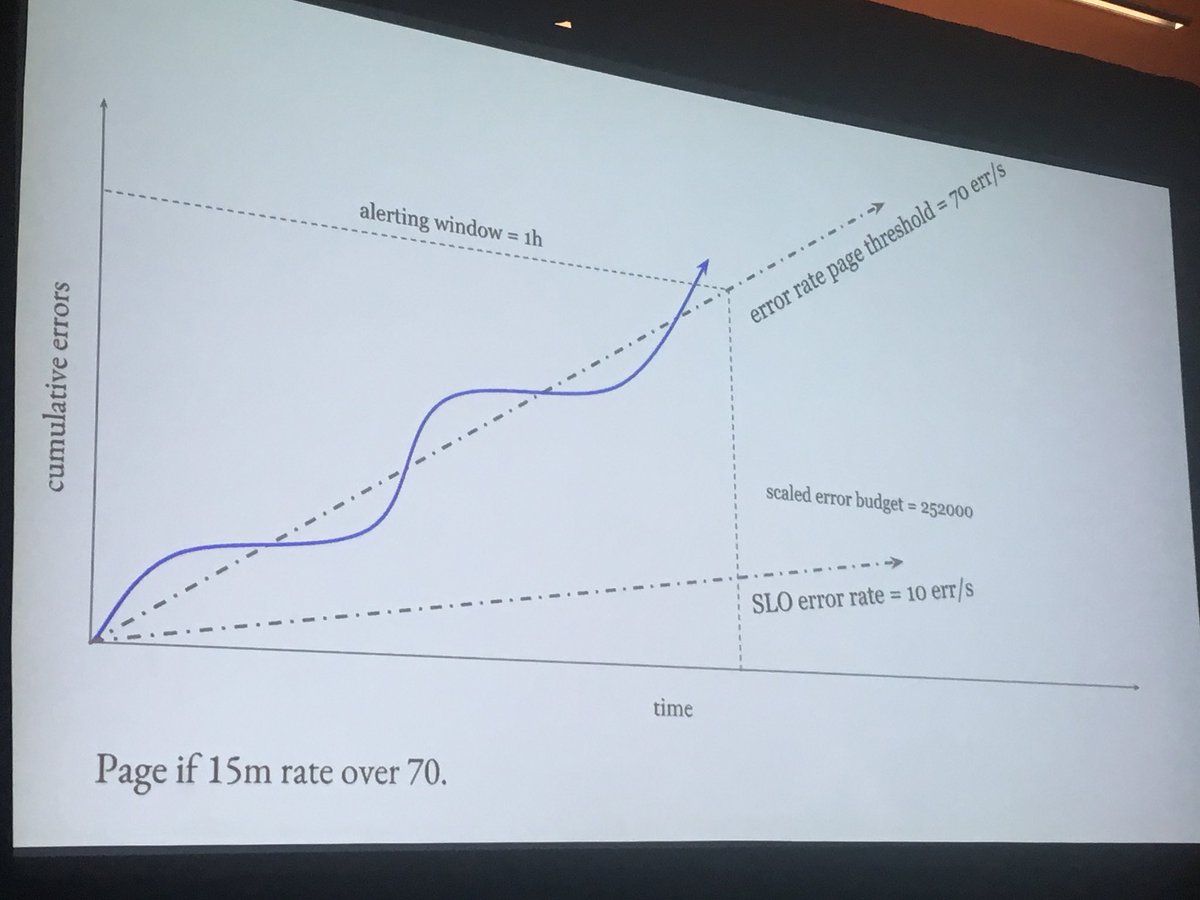
The cumulative errors graph is the total number of errors received by the system
The third graph is the estimated threshold to alert at if the burn rate is exceeded in the next 24 hours
The cumulative errors graph is the total number of errors received by the system
The third graph is the estimated threshold to alert at if the burn rate is exceeded in the next 24 hours
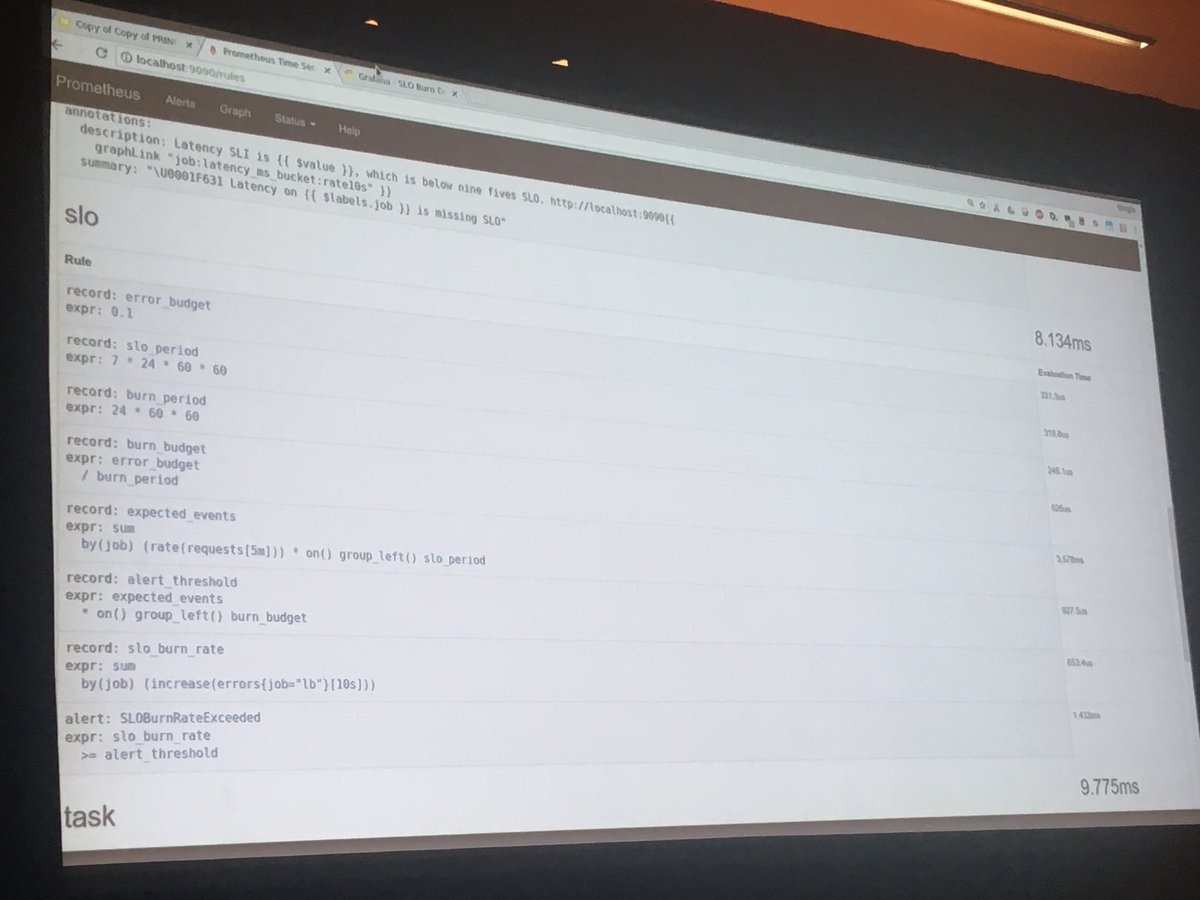
In a single process, you can attach GDB as a sidecar and observe what’s happening in the system.
For a distributed systems, there are there signals one generally emits - logs, metrics and traces (all a derivative of events). #velocityconf
For a distributed systems, there are there signals one generally emits - logs, metrics and traces (all a derivative of events). #velocityconf
Observability is the same as debugging. It’s an emerging property of a system.
Monitoring and alerting isn’t a substitute to debugging
Also, a classic @allspaw quote from @Monitorama
#velocityconf
Monitoring and alerting isn’t a substitute to debugging
Also, a classic @allspaw quote from @Monitorama
#velocityconf

“I go on call because it’s a tool for improving the product - not because I *likeI being on call” - @jaqx0r at #velocityconf
At google, there’s a limit of 2 pages per on-call shift.
At google, there’s a limit of 2 pages per on-call shift.
“At google we talk about this idea of operational excellence - and you can make a career out of it.” -@jaqx0r at #velocityconf
TLDR - Error budgets are way better than cause based alerts. You get paged much less and when you do get paged, it’s for important stuff.
TLDR - Error budgets are way better than cause based alerts. You get paged much less and when you do get paged, it’s for important stuff.

• • •
Missing some Tweet in this thread? You can try to
force a refresh










