
How many random seeds are needed to compare #DeepRL algorithms?
Our new tutorial to address this key issue of #reproducibility in #reinforcementlearning
PDF: arxiv.org/pdf/1806.08295…
Code: github.com/flowersteam/rl…
Blog: openlab-flowers.inria.fr/t/how-many-ran…
#machinelearning #neuralnetworks
Our new tutorial to address this key issue of #reproducibility in #reinforcementlearning
PDF: arxiv.org/pdf/1806.08295…
Code: github.com/flowersteam/rl…
Blog: openlab-flowers.inria.fr/t/how-many-ran…
#machinelearning #neuralnetworks
Algo1 and Algo2 are two famous #DeepRL algorithms, here tested
on the Half-Cheetah #opengym benchmark.
Many papers in the litterature compare using 4-5 random seeds,
like on this graph which suggests that Algo1 is best.
Is this really the case?
on the Half-Cheetah #opengym benchmark.
Many papers in the litterature compare using 4-5 random seeds,
like on this graph which suggests that Algo1 is best.
Is this really the case?

However, more robust statistical tests show there are no differences.
For a very good reason: Algo1 and Algo2 are both the same @openAI baseline
implementation of DDPG, same parameters!
This is what is called a "Type I error" in statistics.
For a very good reason: Algo1 and Algo2 are both the same @openAI baseline
implementation of DDPG, same parameters!
This is what is called a "Type I error" in statistics.
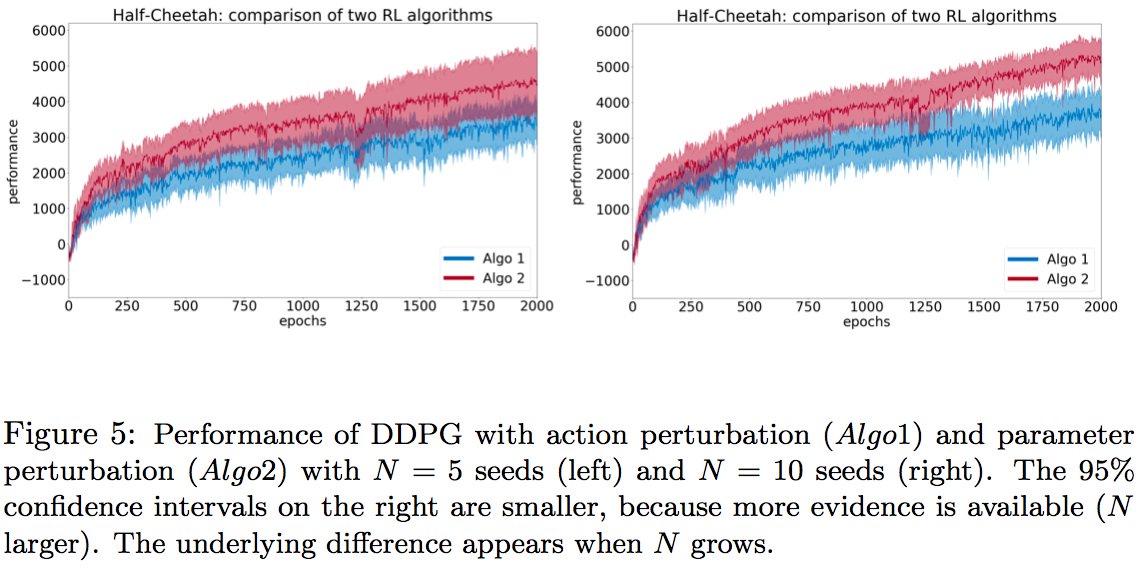
Sometimes, using few random seeds shows no sign of one algorithm being
better or worse than another.
Here, DDPG with action perturb. vs DDPG with parameter perturb. with 5 seeds.
better or worse than another.
Here, DDPG with action perturb. vs DDPG with parameter perturb. with 5 seeds.

This apparent no-difference is a "Type II" error. Using more random seeds, and refined statistical tests, DDPG with parameter perturb. is actually robustly better than DDPG with action perturb.
The tutorial discusses the issue of how many random seeds are needed to compare algorithms, and which statistical method to use to assess the reliability of results.
Nothing is new in this tutorial, and these statistical methods are used widely in biology and physics. But we hope it will be useful!
What is surprising is how rarely they are used in #machinelearning ... which is about statistical learning!
What is surprising is how rarely they are used in #machinelearning ... which is about statistical learning!
If you see things to improve or update, all comments welcome!
You can use the blog to post questions/comments:
openlab-flowers.inria.fr/t/how-many-ran…
You can use the blog to post questions/comments:
openlab-flowers.inria.fr/t/how-many-ran…
Last but not least, congrats to Cedric Colas for the outstanding work on this project!
A few great links about the problem of #reproducibility in #deepRL:
amid.fish/reproducing-de…
arxiv.org/abs/1709.06560
@icmlconf workshop: sites.google.com/view/icml-repr…
amid.fish/reproducing-de…
arxiv.org/abs/1709.06560
@icmlconf workshop: sites.google.com/view/icml-repr…
• • •
Missing some Tweet in this thread? You can try to
force a refresh



