1) @ProjectJupyter Extension of the Day: Spellchecker!
This #nbextension uses a @CodeMirror overlay mode to highlight incorrectly-spelled words in Markdown and Raw cells. The typo.js library does the actual spellchecking, and is included as a dependency.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
This #nbextension uses a @CodeMirror overlay mode to highlight incorrectly-spelled words in Markdown and Raw cells. The typo.js library does the actual spellchecking, and is included as a dependency.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
.@ProjectJupyter Extension of the Day #2: Codefolding!
This extension adds codefolding functionality from @CodeMirror to each code cell in your notebook. The folding status is saved in the cell metadata, so reloading a notebook restores the folded view.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
This extension adds codefolding functionality from @CodeMirror to each code cell in your notebook. The folding status is saved in the cell metadata, so reloading a notebook restores the folded view.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
.@ProjectJupyter Extension of the Day #3: ExecuteTime!
This extension displays when the last execution of a code cell occurred and how long it took. The timing information is stored in the cell metadata, restored on notebook load, & can be togged on/off.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
This extension displays when the last execution of a code cell occurred and how long it took. The timing information is stored in the cell metadata, restored on notebook load, & can be togged on/off.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
.@ProjectJupyter Extension of the Day #4: nbTranslate!
This extension converts markdown cells in a notebook from one language to another & enables one to selectively display cells from a given language in a multilanguage notebook. LaTeX is also supported.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
This extension converts markdown cells in a notebook from one language to another & enables one to selectively display cells from a given language in a multilanguage notebook. LaTeX is also supported.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
.@ProjectJupyter Extension of the Day #5: Hinterland!
This extension enables a code autocompletion menu for every keypress in a code cell, instead of only calling it with tab. It also displays helpful tooltips based on customizable timed cursor placement.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
This extension enables a code autocompletion menu for every keypress in a code cell, instead of only calling it with tab. It also displays helpful tooltips based on customizable timed cursor placement.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
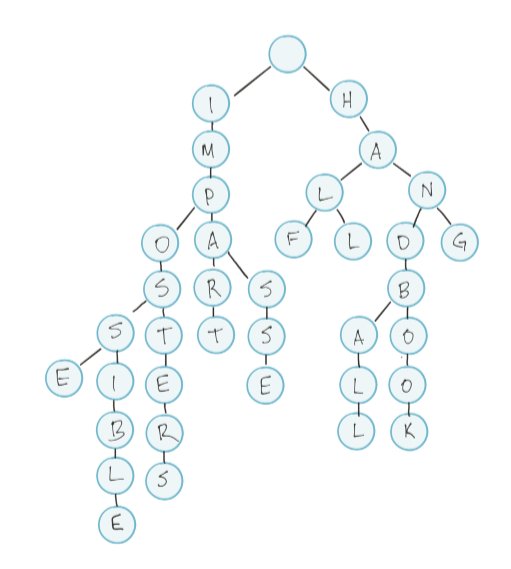
PS: if you've ever wondered how Intellisense works, or how search engines are able to autocomplete so quickly - it's all due to tries!
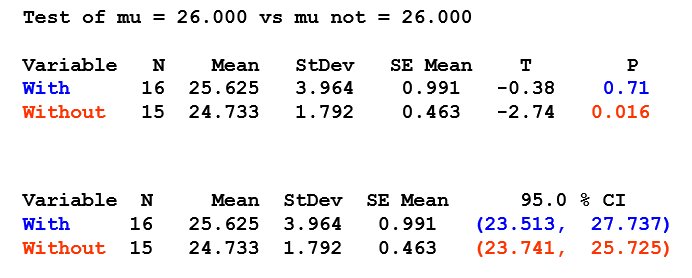
Advantages: speed, space, & partial matching. Finding a word in this structure is O(m), where m is the length of the word you’re trying to find.
Advantages: speed, space, & partial matching. Finding a word in this structure is O(m), where m is the length of the word you’re trying to find.
.@ProjectJupyter Extension of the Day #6: highlighter!
This extension provides several toolbar buttons for highlighting text within markdown cells. Highlights can also be preserved when exporting to HTML or #LaTeX, and color schemes are customizable.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
This extension provides several toolbar buttons for highlighting text within markdown cells. Highlights can also be preserved when exporting to HTML or #LaTeX, and color schemes are customizable.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
...and because I am horrific at Twitter threads:
External Tweet loading...
If nothing shows, it may have been deleted
by @DynamicWebPaige view original on Twitter
.@ProjectJupyter Extension of the Day #7: 2to3!
This nbextension converts python2 in notebook cells to python3 code.
Under the hood, it uses a call to the notebook kernel for reformatting; & the conversion run by the kernel uses the stlib lib2to3 module.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
This nbextension converts python2 in notebook cells to python3 code.
Under the hood, it uses a call to the notebook kernel for reformatting; & the conversion run by the kernel uses the stlib lib2to3 module.
…r-contrib-nbextensions.readthedocs.io/en/latest/nbex…
• • •
Missing some Tweet in this thread? You can try to
force a refresh