Discover and read the best of Twitter Threads about #rstats
Most recents (19)

over in Slack-land a colleague asked for resources on learning #rstats, with a particular emphasis on resources aimed at beginners.
🌟SO🌟
here is a thread of my personal favorites:
🌟SO🌟
here is a thread of my personal favorites:
Modern Dive is 🙌🙌🙌 and probably one of the best "I NEED TO LEARN DATA SCIENCE IN R RIGHT MEOW" resources out there because it gets you up, running, and through the whole DS cycle pretty quickly.
moderndive.com
moderndive.com
R for Data Science is perfect for leveling up your R skills in an applied context, and gives you plenty of practice exploring the tidyverse 🌌
r4ds.had.co.nz
r4ds.had.co.nz

For #DeclareDesign #launchday, here’s a thread about our five #rstats packages for research design and analysis: DeclareDesign, fabricatr, estimatr, randomizr, and DesignLibrary.
5 📦’s in 5 📣’s!
@graemedblair @jasperjcooper @maqartan
5 📦’s in 5 📣’s!
@graemedblair @jasperjcooper @maqartan
DeclareDesign is “ggplot for research designs.” You add together design elements – data generating processes, sampling and assignment schemes, and estimators to declare a design. declaredesign.org/r/declaredesig… 




fabricatr simulates fake data to help imagine your data before you collect it, especially hierarchical data common in the social sciences (students in classes in schools). Aaron Rudkin and Neal Fultz deserve big credit for development. declaredesign.org/r/fabricatr/


If you want to make code/data “available”, GitHub isn’t enough.
You must deposit at a DOI-issuing data repository @figshare & @ZENODO_org are both free & awesome; can be synced w/ a GitHub repo
Why GitHub not enough? 1/4
#OpenAccess #OpenData
You must deposit at a DOI-issuing data repository @figshare & @ZENODO_org are both free & awesome; can be synced w/ a GitHub repo
Why GitHub not enough? 1/4
#OpenAccess #OpenData
GitHub is a place for things to be worked on, not for them to live forever.
- Links are fragile (username, repo name)
- Users can delete repos
- GitHub could make your code/data unavailable in the future.
DOI-issuing data repositories preserve your stuff for the future 2/4
- Links are fragile (username, repo name)
- Users can delete repos
- GitHub could make your code/data unavailable in the future.
DOI-issuing data repositories preserve your stuff for the future 2/4
Depositing on @KaggleDatasets isn’t good enough for #OpenAccess #OpenData either.
- No API for accessing files without an account
- Fragile URLs
- Kaggle Datasets is a commercial thing.
Do all three! GitHub repo, Kaggle Dataset and @figshare or @ZENODO_ORG 3/4
- No API for accessing files without an account
- Fragile URLs
- Kaggle Datasets is a commercial thing.
Do all three! GitHub repo, Kaggle Dataset and @figshare or @ZENODO_ORG 3/4

What does one get when mindlessly applying logistic regression to a too small dataset? Well…
[thread]
[thread]
Just to be clear, I have zero interest in shaming these authors. Small sample logistic regression analyses are very common! But for those of you interested here is the link: journalacs.org/article/S1072-…
“The aim of this study was to evaluate the impact of medical student placement of Foley catheters on rates of postoperative catheter-associated urinary tract infection (CAUTI)”.

Getting ready to teach dplyr joins to new #rstats users tomorrow, so naturally I productively procrastinated by getting to know the new gganimate. It is the coolest!
The readme is a great intro -- github.com/thomasp85/ggan…. I basically just replaced `+facet_wrap(~ key)` with `+transition_states(key)`.
I really like how easily the gganimate calls fit in with the ggplot pipeline. It's very clear @thomasp85 put a lot of thought and care into the API design.

Thread: Though there is lots of community interest in model-agnostic model explanations (eg. LIME), I’ve been interested in an explainer specific to random forests. Came across a great one here: github.com/MI2DataLab/ran… #rstats
To begin, train an RF model and run the explain_forest() function. #rstats

Next thing you know, a variety of “views” into the forest appear on your machine. Can explore interactions between metrics and variables. For more details, check out this vignette: rawgit.com/MI2DataLab/ran… #rstats
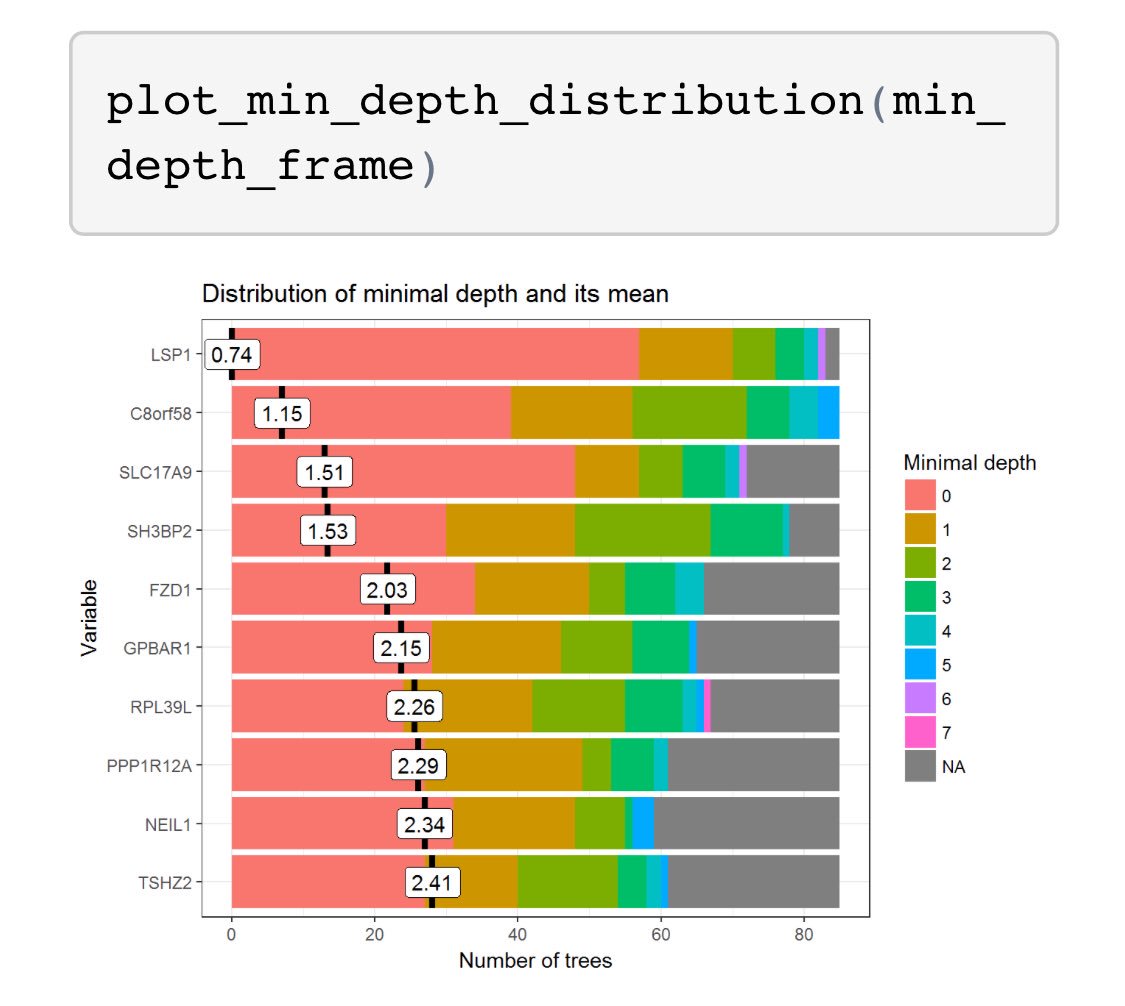
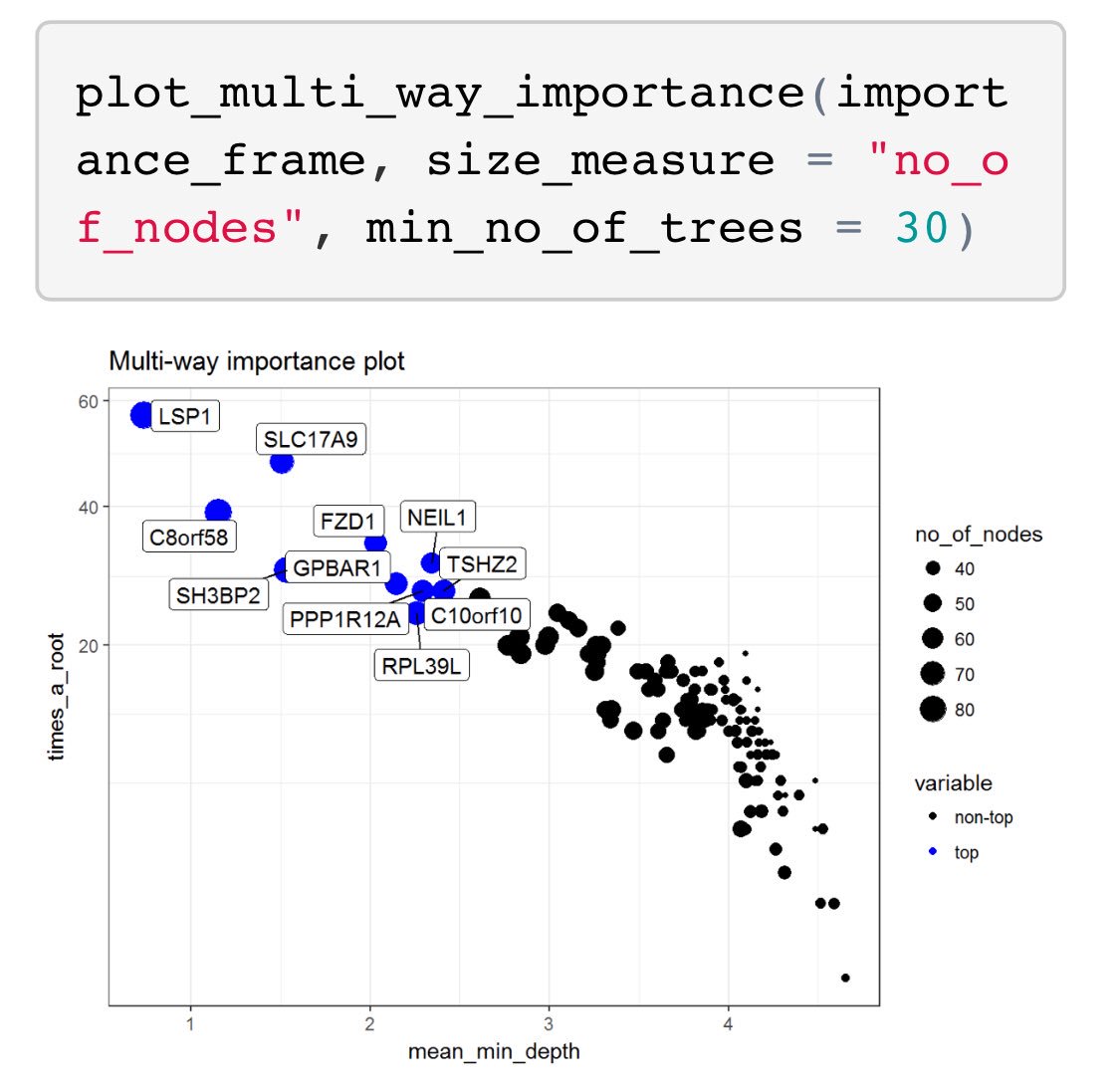
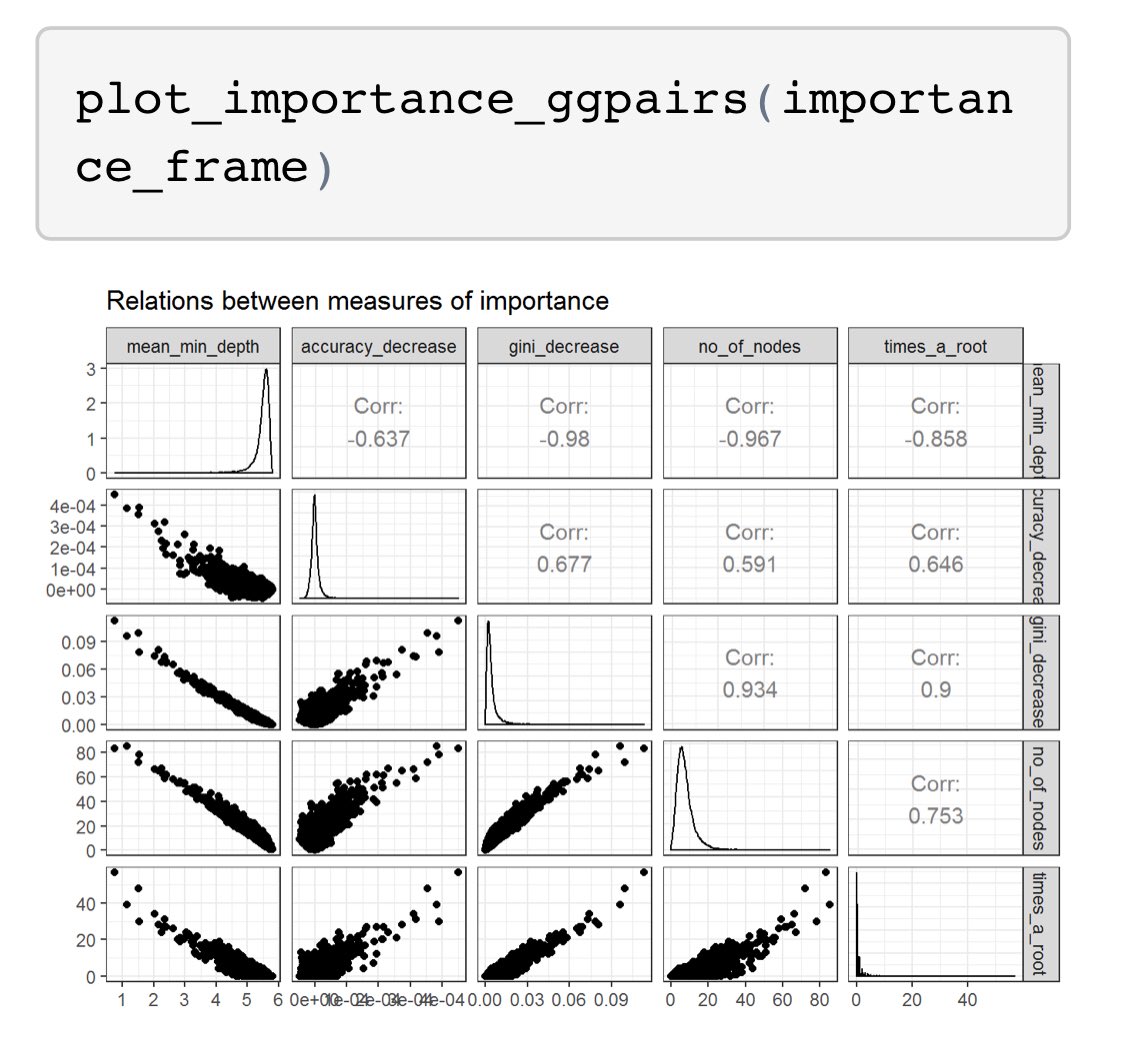
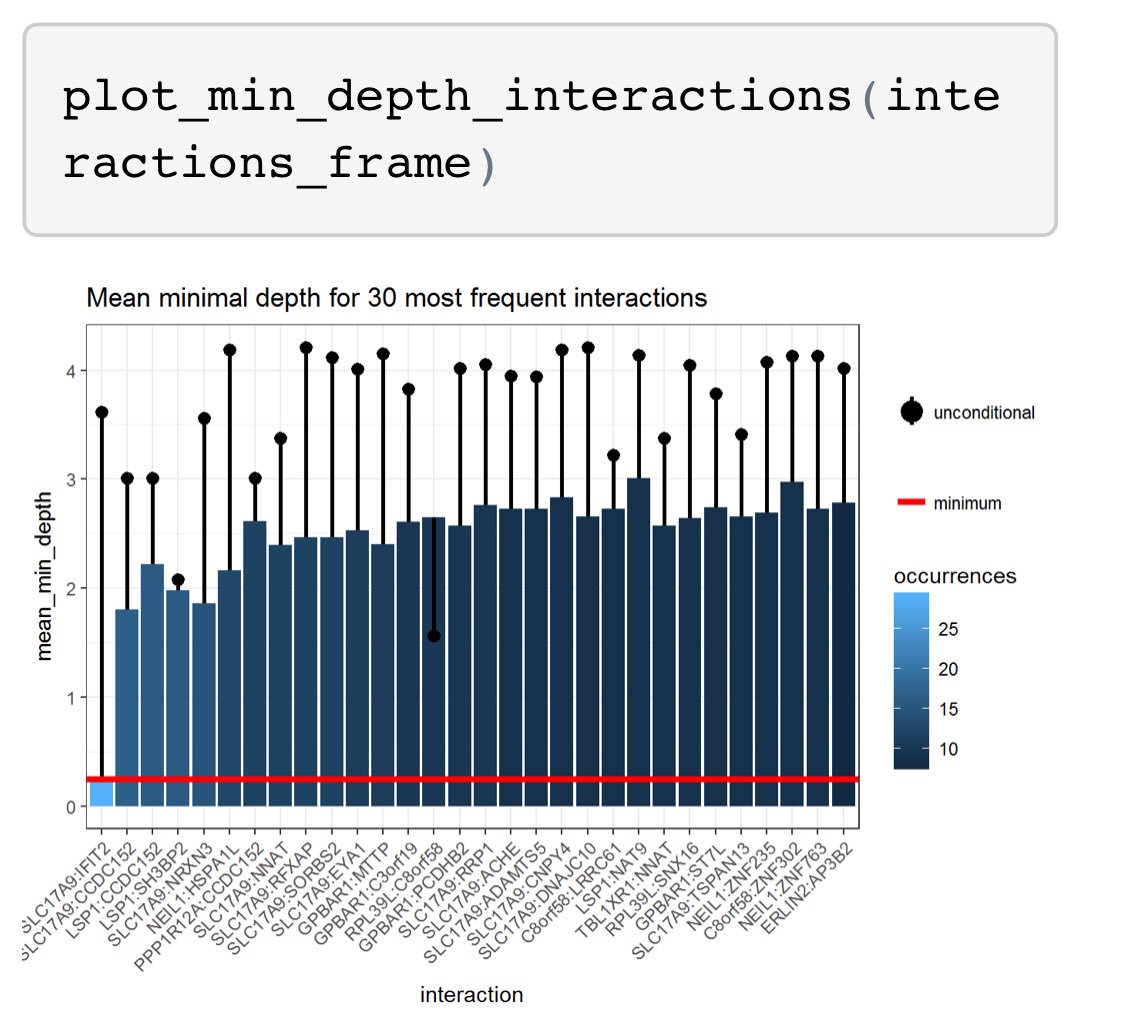


At the end of June, there were around 12500 📦 on the CRAN


#NowWatching — @TrestleJeff, talking about {plumber} 🛠⚙️register.gotowebinar.com/register/55312…
#RStats #RStudio #Webinar
#RStats #RStudio #Webinar
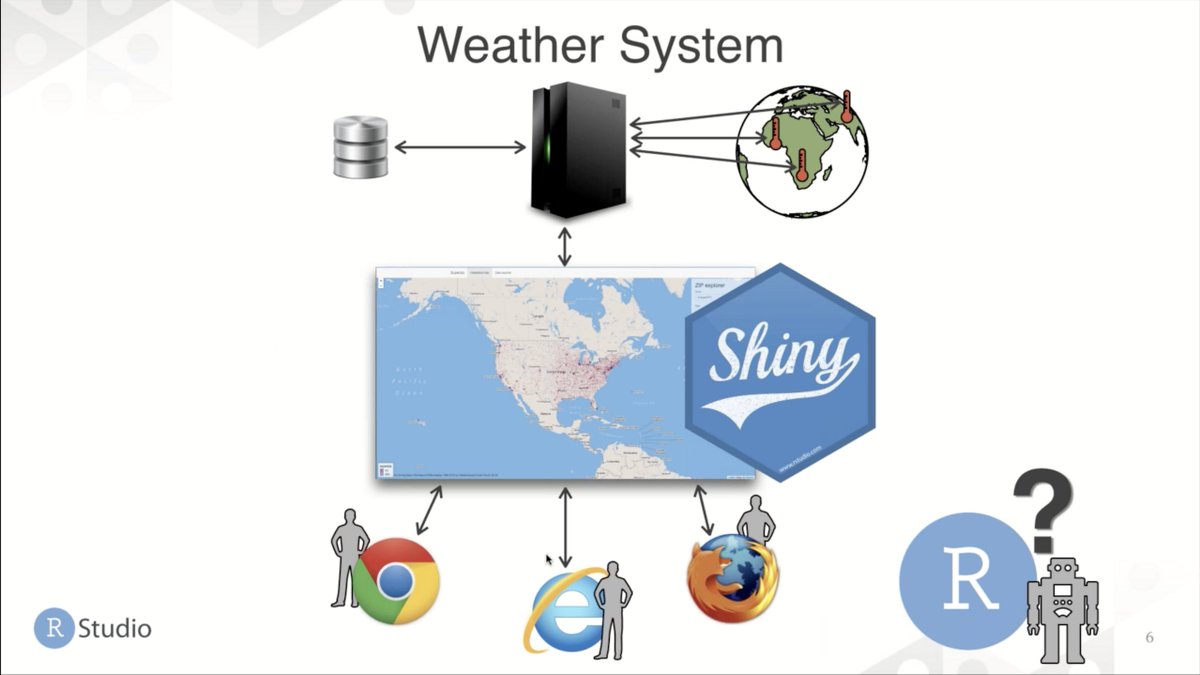
💬 "If you're aiming at humans only, you can build a shiny app. If you want machines to access your data, build an API"
💬 "And remember that any other language can access your R API. You're opening a lot of doors."
#RStats
💬 "And remember that any other language can access your R API. You're opening a lot of doors."
#RStats
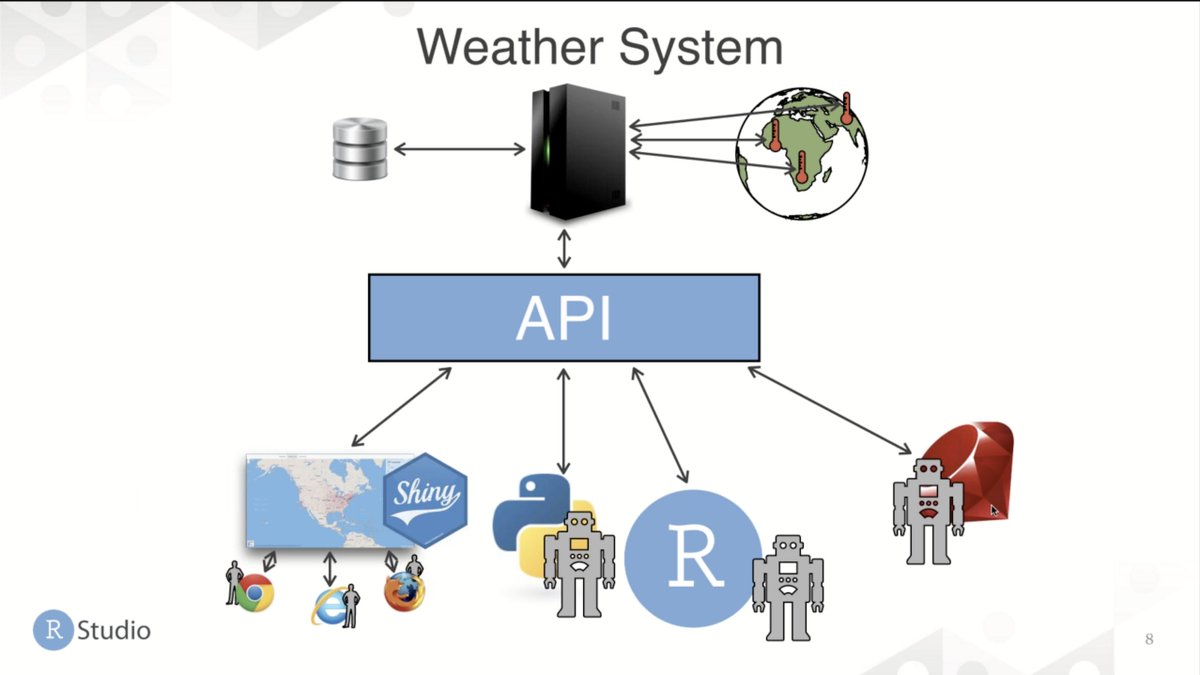
Some important things to know when working with APIs:
🕸 About http requests : developer.mozilla.org/en-US/docs/Web…
🚀 About REST API : en.wikipedia.org/wiki/Represent…
🕸 About http requests : developer.mozilla.org/en-US/docs/Web…
🚀 About REST API : en.wikipedia.org/wiki/Represent…

[Thread #RStats #Programming ]
Some important points taken from "Object-Oriented Programming, Functional Programming and R", by John M. Chambers
arxiv.org/pdf/1409.3531.…
Some important points taken from "Object-Oriented Programming, Functional Programming and R", by John M. Chambers
arxiv.org/pdf/1409.3531.…
An article about what is Functional Programming (FP), and how does it differ from Object Oriented Programming (OOP) ?
Note that both these paradigms are used in R, and interact with each others.
Note that both these paradigms are used in R, and interact with each others.
Here’s the definition of what FP is :
- Programming == creating function
- Functions returns values computed from arguments (and only these)
- A function has no side effect
- Programming == creating function
- Functions returns values computed from arguments (and only these)
- A function has no side effect

It’s an historical choice: R comes from S, which used <- for assignment. S uses `<-` partly because it is inspired by APL, which had the ← operator for assignment, as it was developed for this keyboard, which has a key for arrow :
en.wikipedia.org/wiki/APL_(prog…
en.wikipedia.org/wiki/APL_(prog…
Not that at that time, with APL, the arrow was chosen because it distinguished from the equal operator (there were no `==` for testing equality).
See : softwarepreservation.org/projects/apl/B…
See : softwarepreservation.org/projects/apl/B…


⬇️ Thread of thoughts on this topic ⬇️
I've taught #D3js to nearly 300 faculty, staff, and students at primarily the grad/PhD level across various workshops and bootcamps.
Some key reasons behind why D3 is hard, I'll outline below (in case anyone is learning or curious)
I've taught #D3js to nearly 300 faculty, staff, and students at primarily the grad/PhD level across various workshops and bootcamps.
Some key reasons behind why D3 is hard, I'll outline below (in case anyone is learning or curious)
While you DO need to understand empathy, design, color perception, visual cognition, story-telling, geometric thinking, graphical conventions, basic statistics, data structures, linear/spatial algebra, and trigonometry to do VISUALIZATION well, D3 makes all of this *EVEN HARDER*




Why? Because the CORE of D3 is in its name: 'Data Driven Documents.' Data-driven is one thing, but the 'Documents' part refers to the DOM, which is a broad term referring to the *stuff* that makes up the web:
HTML
CSS
SVG/XML
Canvas
JavaScript
& more - all at once
HTML
CSS
SVG/XML
Canvas
JavaScript
& more - all at once


So folks, what package would you recommend for paralellising code in R?
I thought this would be simple based on previous experience with parallelising code but I am quickly realising it is not going to be simple. Blargh.
I have had a total turnaround and now think I do not need the paralell package.
I hope you are all enjoying this live commentary on the realities of science.
I hope you are all enjoying this live commentary on the realities of science.
So far, I've got:



Now comes the hard part of being an academic #opensource developer moving into industry. 😢 I need volunteers to take over some of my #rstats packages. I'm hoping to retain some but also want to pass on a few.
If you're interested, please reach out on Github about any of...
If you're interested, please reach out on Github about any of...
{csvy} is a package for reading and writing metadata-enhanced CSV files that include a YAML header.
The format: csvy.org
The package: github.com/leeper/csvy (on CRAN but needs some updates to match the current csvy specification).
The format: csvy.org
The package: github.com/leeper/csvy (on CRAN but needs some updates to match the current csvy specification).
{colourlovers} is an API client for colourlovers.com
The package: cran.r-project.org/web/packages/c… (on CRAN but could use an XML -> xml2 conversion and a refresh to make sure it's still up to date).
The package: cran.r-project.org/web/packages/c… (on CRAN but could use an XML -> xml2 conversion and a refresh to make sure it's still up to date).

If you’re an academic you need a website so that people can easily find info about your research and publications. Here’s how to make your own website for free in an under an hour using the blogdown package in #Rstats [THREAD]
So why use blogdown? Sure, there are several free options available to start your own blog (e.g., Medium). However, you generally can’t list your publications or other information easily on these services. Also, who knows where these services will be in a few years?
There are also some great point-and-click services available (e.g., Squarespace). However, you need to pay about $10 a month for these services, and they’re generally not well suited for academic webpages.
Funnel plots are often used to assess publication bias in meta-analysis, but these plots only visualise *small study* bias, which may or may not include publication bias. Here's a guide on making contour-enhanced funnel plots in #Rstats, which better visualise publication bias
First, some background.... Publication bias is a well-known source of bias. For instance, researchers might shelve studies that aren’t statistically significant, as journals are unfortunately less likely to publish these kind of results.
Researchers might also use questionable research practices — also known as p-hacking — to nudge an effect across the line to statistical significance
Here are ten things I’ve changed my mind about in the last few years of being a scientist
1. P-values are bad.
Nope. P-values are good for what they’re designed to do. Just because they’re (often) misused doesn’t mean that we should abandon them.
Nope. P-values are good for what they’re designed to do. Just because they’re (often) misused doesn’t mean that we should abandon them.
2. Bayes factors will save us from the misuse of p-values
No. Bayes factors *can* be useful, but they’re not always the solution to p-value limitations.
No. Bayes factors *can* be useful, but they’re not always the solution to p-value limitations.
I’ve peer reviewed A LOT of meta-analyses over the past few years. While I’ve noticed that the overall quality of meta-analyses are improving, many that I review suffer from the same issues. Here’s a thread listing the most common problems and how to avoid them
#1 Not using PRISMA reporting guidelines (or stating that PRISMA guidelines were followed, but not *actually* following them).
prisma-statement.org/Default.aspx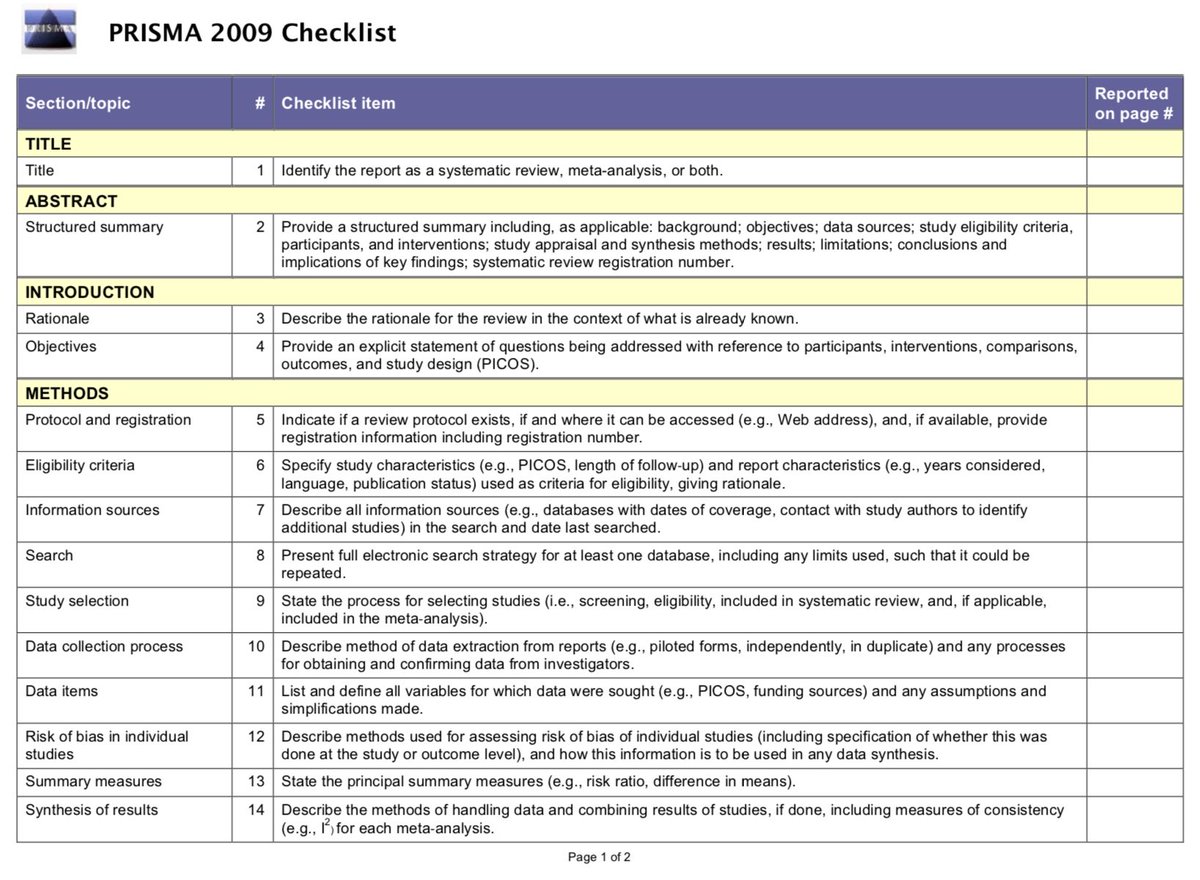
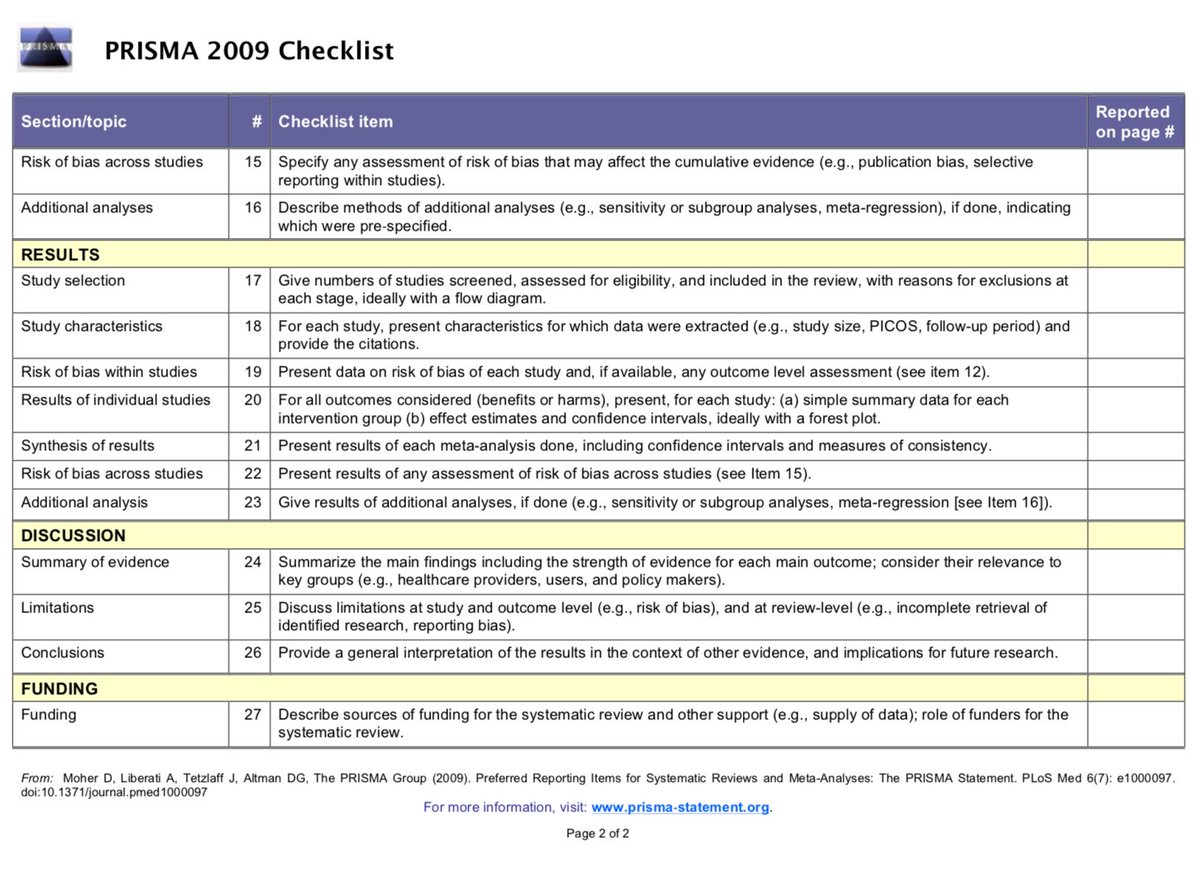
prisma-statement.org/Default.aspx
These guidelines provide a framework for the transparent reporting of meta-analysis, which can help the reader assess the strengths/weaknesses of a meta-analysis.

Lifting other scholars up is such a powerful action in the quest to push against the type of academia we dislike. Promote *other* scholars.
Consistently, @maya_sen has been promoting up-and-coming early career political scientists (alongside @JohnHolbein1 and others too ❤️)

#/media/File:APL-keybd2.svg){kind=link}